DETR
能够消除物体检测中许多手工设计组件的需求,同时展示良好的性能。但由于注意力模块在处理图像特征图方面的限制,
DETR
存在收敛速度慢和特征分辨率有限的问题。为了缓解这些问题,论文提出了
Deformable DETR
,其注意力模块仅关注参考点周围的一小组关键采样点,通过更少的训练次数实现比
DETR
更好的性能来源:晓飞的算法工程笔记 公众号
论文: Deformable DETR: Deformable Transformers for End-to-End Object Detection

-
论文地址:
https://arxiv.org/abs/2010.04159
-
论文代码:
https://github.com/fundamentalvision/Deformable-DETR
Introduction
现代物体检测器采用许多手工制作的组件,例如锚点生成、基于规则的训练目标分配、非极大值抑制 (
NMS
) 后处理,导致其并不是完全端到端的。
DETR
的提出消除了对此类手工制作组件的需求,并构建了第一个完全端到端的物体检测器。
DETR
采用简单的架构,结合卷积神经网络 (
CNN
) 和
Transformer
编码器-解码器,利用
Transformer
的多功能且强大的关系建模功能,达到了很不错的性能。
尽管
DETR
具有有趣的设计和良好的性能,但它也有自己的问题:(1)需要更长的训练周期才能收敛。(2)
DETR
在检测小物体方面的性能相对较低,没有利用多尺度特征。
上述问题主要归因于
Transformer
组件在处理图像特征图方面的缺陷。在初始化时,注意力模块将几乎统一的注意力权重投射到特征图中的所有像素。长时间的训练对于注意力权重学习如何关注稀疏的有意义的位置是必要的。另一方面,
Transformer
编码器中的注意力权重计算与像素成二次计算度。因此,处理高分辨率特征图的计算和存储复杂度非常高。
在图像领域,可变形卷积是处理稀疏空间位置的强大而有效的机制,自然就避免了上述问题。但它缺乏元素关系建模机制,而这正是
DETR
成功的关键。

在本文中,论文提出了
Deformable DETR
,结合可变形卷积的稀疏空间采样和
Transformers
的关系建模能力,缓解了
DETR
收敛速度慢和计算复杂度高的问题。可变形注意模块仅关注一小组采样位置,相当于所有特征图像素中突出关键元素的预过滤器。该模块可以自然地扩展到多尺度特征架构,而无需
FPN
的帮助。在
Deformable DETR
中,论文利用(多尺度)可变形注意力模块来代替处理特征图的
Transformer
注意力模块,如图 1 所示。
Revisiting Transformers and DETR
Multi-Head Attention in Transformers.
定义
\(q\in\Omega_{q}\)
为查询元素下标,索引特征
\({z}_{q}\in {\mathbb{R}}^C\)
,
\(k\in\Omega_{k}\)
为键元素下标,索引特征
\(x\_k \in \mathbb{R}^C\)
,
\({C}\)
是特征维度,
\(\Omega_{q}\)
和
\(\Omega\_{k}\)
分别为查询元素和键元素的集合。
多头注意力特征的计算可表示为:
其中
\(m\)
为注意力头下标,
\(W_{m}^{\prime}\in\mathbb{R}^{C_{v}\times C}\)
和
\(W_{m}\in{\mathbb{R}^{{C}\times C_{v}}}\)
为可学习的权重(默认
\({C}_{v}=C/M\)
)。注意力权重
\(A_{m q k}\propto{exp}\lbrace\frac{z_{q}^{T}\,U_{m}^{T}\,\,V_{m}\,x_{k}}{\sqrt{C_{v}}}\rbrace\)
归一化为
\(\sum_{k\in\Omega_k}A_{mqk}=1\)
,其中
\(U_{m},V_{m}\in\mathbb{R}^{C_{v}\times C}\)
也是可学习的权重。为了区别不同的空间位置,特征
\({z}_{q}\)
和
\({z}\_{k}\)
通常是元素内容和位置嵌入的串联或求和。
Transformer
有两个已知问题:1)收敛需要很长的训练周期。2)多头注意力的计算和内存复杂度可能非常高。
DETR
DETR
建立在
Transformer
编码器-解码器架构之上,与基于集合的匈牙利损失相结合,通过二分匹配强制对每个
GT
的边界框进行预测。对
DETR
不熟悉的,可以看看之前的文章,【
DETR:Facebook提出基于Transformer的目标检测新范式 | ECCV 2020 Oral
】。
给定
CNN
主干网提取的输入特征图
\(x\in\mathbb{R}^{C\times H\times W}\)
,
DETR
利用标准
Transformer
编码器-解码器架构将输入特征图转换为一组对象查询的特征。在对象查询特征(由解码器产生)之上添加一个 3 层前馈神经网络(
FFN
)和一个线性投影作为检测头。
FFN
充当回归分支来预测边界框坐标
\(b\in 0, 1^4\)
,其中
\(b = {b_{x},b_{y},b_{w},b_{h}}\)
编码归一化的框中心坐标、框高度和框宽度(相对于图像大小),线性投影则作为分类分支来产生分类结果。
对于
DETR
中的
Transformer
编码器,查询元素和键元素都是主干网络特征图中的像素(带有编码的位置嵌入)。
对于
DETR
中的
Transformer
解码器,输入包括来自编码器的特征图和由可学习位置嵌入表示的
N
个对象查询。解码器中有两种类型的注意力模块,即交叉注意力模块和自注意力模块。
- 在交叉注意力模块中,查询元素为学习到的对象查询,而键元素是编码器的输出特征图。
- 在自注意力模块中,查询元素和键元素都是对象查询,从而捕获它们的关系。
DETR
是一种极具吸引力的物体检测设计,无需许多手工设计的组件,但也有自己的问题:1)由于计算复杂度限制其可使用分辨率的大小,导致
Transformer
在检测小物体方面的性能相对较低。2)因为处理图像特征的注意力模块很难训练,
DETR
需要更多的训练周期才能收敛。
METHOD

Deformable Transformers for End-to-End Object Detection
- Deformable Attention Module
在图像特征图上应用注意力计算的核心问题是,它会遍历所有的空间位置。为了解决这个问题,论文提出了一个可变形的注意力模块。受可变形卷积的启发,可变形注意力模块仅关注参考点周围的一小组关键采样点,而不管特征图的空间大小。如图 2 所示,通过为每个查询元素仅分配少量的键元素,可以缓解收敛慢和特征空间分辨率大的问题。
给定输入特征图
\(x\in\mathbb{R}^{C\times H\times W}\)
,
\(q\)
为查询元素的下标,对应内容特征
\({z}_{q}\)
和二维参考点
\({p}_{q}\)
,可变形注意力特征的计算如下
其中
\(m\)
为注意力头下标,
\(k\)
为采样点下标,
\(K\)
为采样点总数(
\(K\ll H W\)
)。
\({\Delta}p_{mqk}\)
和
\(A_{m q k}\)
表示第
k
个采样点的采样偏移及其使用的在第
m
个头中的注意力权重。注意力权重
\(A_{m q k}\)
在
\(0,1\)
范围内,由
\(\sum_{k=1}^{K}A_{m q k} = 1\)
归一化。
\({\Delta}p_{mqk}\in \mathbb{R}^{2}\)
是无约束范围的二维实数,由于
\(p_{q} + \Delta p_{mqk}\)
是小数,需要应用双线性插值。
\(\Delta p_{m q k}\)
和
\(A_{mqk}\)
均通过对查询特征
\({z}_{q}\)
的线性投影获得的。在实现中,查询特征
\(z_{q}\)
被输入到
\(3MK\)
通道的线性投影运算符,其中前
\(2MK\)
通道对
\({\Delta}P_{m q k}\)
采样偏移进行编码,剩余的
\(MK\)
通道输入到
\(Softmax\)
运算符以获得
\(A_{m q k}\)
注意力权重。

定义
\(N_{q}\)
为查询元素的数量,当
\(M K\)
相对较小时,可变形注意力模块的复杂度为
\(O(2N_{q}C^{2}+\operatorname\*{min}(H W C^{2},N_{q}K C^{2}))\)
。当应用于__
DETR
__编码器时,其中
\(N_{q}=H W\)
,复杂度变为
\(O(H W C^{2})\)
,与空间大小成线性复杂度。当应用于
DETR
解码器中的交叉注意模块时,其中
\(N\_{q}=N\)
(
\(N\)
是对象查询的数量),复杂度变为
\(O(NKC^2)\)
,这与空间大小
\(HW\)
无关。
- Multi-scale Deformable Attention Module
大多数现代目标检测框架都受益于多尺度特征图,论文提出的可变形注意模块也可以自然地扩展到多尺度特征图。
定义
\(\left{x^{l}\right}^{L}_{l=1}\)
为输入的多尺度特征图,其中
\(x^{l}\in \mathbb{R}^{C\times H_{l}\times W_{l}}\)
。定义
\({\hat{p}}_{q}\in0,1^{2}\)
为每个查询元素
\(q\)
对应的参考点的归一化坐标,多尺度可变形注意模块的计算为:
其中
\(m\)
为注意力头下标,
\(l\)
为输入特征级别下标,
\(k\)
为采样点下标。
\(\Delta p_{mlqk}\)
和
\(A_{mlqk}\)
表示第
\({{k}}^{th}\)
个采样点在第
\({{l}}^{th}\)
个特征级别和第
\({{m}}^{th}\)
个注意头中的采样偏移和注意力权重,其中标量注意力权重
\(A_{mlqk}\)
由
\(\sum^L_{l=1}\sum^K_{k=1}A_{mlqk}=1\)
归一化。为了缩放方便,使用归一化的坐标
\({\hat{p}}_{q}\in0,1^{2}\)
,其中
\((0,0)\)
和
\((1,1)\)
分别表示图像的左上角和右下角。公式 3 中的函数
\(\phi_{l}{({\hat{p}}_{q})}^{\cdot}\)
将归一化坐标
\({\hat{p}}_{q}\)
重新缩放到第
\({l}^{th}\)
级别的输入特征图的坐标。多尺度可变形注意力与之前的单尺度版本非常相似,只是它从多尺度特征图中采样
\(LK\)
个点,而不是仅从单尺度特征图中采样
\(K\)
个点。
当
\(L=1\)
,
\(K=1\)
以及将
\(W^{‘}_{m}\in \mathbb{R}^{{C}_{v}\times C}\)
固定为单位矩阵时,论文所提出的注意力模块即退化为可变形卷积。
可变形卷积是针对单尺度输入而设计的,每个注意力头仅关注一个采样点,而论文的多尺度可变形注意力会关注来自多尺度输入的多个采样点。(多尺度)可变形注意模块也可以被视为
Transformer
注意力的有效变体,可变形采样位置相当于引入预过滤机制。当采样点为所有位置时,可变形注意力模块相当于
Transformer
注意力。
- Deformable Transformer Encoder
将
DETR
中处理特征图的注意力模块替换为多尺度可变形注意力模块,编码器的输入和输出都是具有相同分辨率的多尺度特征图。

将
ResNet
的
\(C_3\)
到
\(C\_5\)
阶段的输出特征图,通过
\(1\times 1\)
卷积提取多尺度特征图
\(\left{x^{l}\right}_{l=1}^{L-1}\)
(
\(L=4\)
),其中
\(C_{l}\)
的分辨率为输入图像的
\(2^{l}\)
倍降采样。最低分辨率特征图
\(x^{L}\)
是通过对
\(C\_5\)
阶段的输出进行步幅为 2 的
\(3\ \times\ 3\)
卷积获得,表示为
\(C_{6}\)
阶段。所有多尺度特征图都是
\(C=256\)
通道。这里没有使用类似
FPN
的自上而下结构,因为论文提出的多尺度可变形注意力本身就可以在多尺度特征图之间交换信息,添加
FPN
并不会提高性能。
在编码器中应用多尺度可变形注意力模块时,输出是与输入具有相同分辨率的多尺度特征图,键和查询元素都是来自多尺度特征图的像素。对于每个查询像素,参考点是其本身。为了确定每个查询像素位于哪个特征级别,除了位置嵌入之外,还在特征中添加了尺度级别嵌入
\(e\_{l}\)
。与固定编码的位置嵌入不同,尺度级嵌入是随机初始化并与网络联合训练的。
- Deformable Transformer Decoder
解码器中有交叉注意力和自注意力模块,两种类型的注意力模块的查询元素都是对象查询。在交叉注意力模块中,键元素是编码器的输出特征图,对象查询通过与特征图交互提取特征。而在自注意力模块中,键元素也是对象查询,对象查询即相互交互提取特征。
由于可变形注意模块的设计初衷是将卷积特征图作为键元素,因此论文仅将交叉注意模块替换为多尺度可变形注意模块,保持自注意模块不变。对于每个对象查询,参考点
\({\hat{p}}\_{q}\)
的二维归一化坐标是通过带
\(\mathrm{sigmoid}\)
函数的可学习线性投影从对象查询嵌入中预测的。
由于多尺度可变形注意模块提取参考点周围的图像特征,论文将参考点作为边界框中心的初始猜测,然后检测头预测边的相对偏移量。这样,不仅能够降低优化难度,还能让解码器注意力将与预测的边界框具有很强的相关性,加速训练收敛。
Additional Improvements and Variants for Deformable DETR
由于其快速收敛以及高效率的计算,可变形
DETR
为各种端到端目标检测器的变体提供了可能性,比如:
- Iterative Bounding Box Refinement:通过级联的方式,每层解码器优化前一层的预测结果。
- Two-Stage Deformable DETR:通过两阶段检测的方式,选择第一阶段预测的高分区域提案作为第二阶段解码器的对象查询。
EXPERIMENT

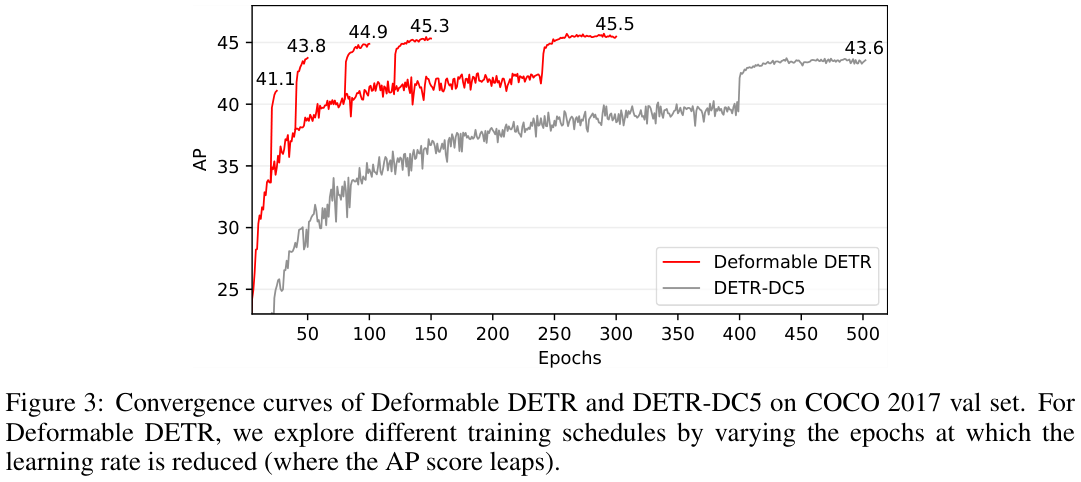
表 1 展示了与
Faster R-CNN
+
FPN
、
DETR
的性能对比。
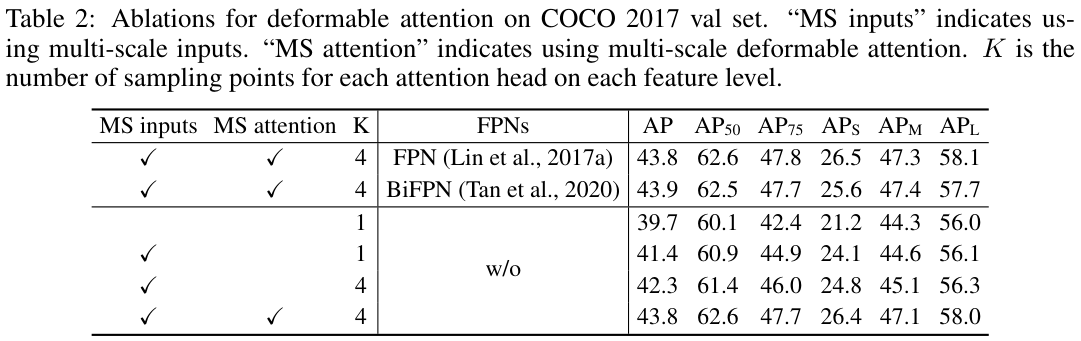
表 2 列出了所提出的可变形注意模块的各种设计选择的消融实验。

表 3 与其他最先进的方法进行了比较。
如果本文对你有帮助,麻烦点个赞或在看呗~undefined更多内容请关注 微信公众号【晓飞的算法工程笔记】
未经允许不得转载:大白鲨游戏网 » Deformable DETR:商汤提出可变型 DETR,提点又加速 | ICLR 2021 Oral

 和平精英巡查员的衣服怎么获得?巡查员衣服获取方法介绍
和平精英巡查员的衣服怎么获得?巡查员衣服获取方法介绍 原神久岐忍角色等级突破材料一览
原神久岐忍角色等级突破材料一览 《王者荣耀》上官婉儿怎么飞天 三个基本连招口诀推荐
《王者荣耀》上官婉儿怎么飞天 三个基本连招口诀推荐 抖音创作服务平台在哪里打开 创作服务平台功能介绍
抖音创作服务平台在哪里打开 创作服务平台功能介绍
